2017년 'Attention Is All You Need' 논문에서 Transformer 구조를 소개하면서 딥러닝 세계에 많은 영향을 주었습니다.
Transformer에는 3가지 Attention이 있습니다.
- Encoder Self-Attention
- Encoder-Decoder Attention
- Decoder Masked Self-Attention
1. Encoder Self-Attention
"고양이가 생선을 맛있게 먹었다"라는 문장이 있을 때, "먹었다"라는 단어의 의미를 제대로 파악하기 위해서는 "고양이가", "생선을" 등의 다른 단어들과의 관계를 잘 이해해야 합니다. Self-Attention은 이런 방법처럼 문장 내 단어 간의 관계를 스스로 학습해서 문장 내에서 어떤 단어가 중요한지 스스로 판단해 문맥을 이해합니다.
Encoder-Decoder Attention과 차이점은 Self-Attention은 '나는 사과를 먹는다' -> 'I eat an apple'에서 '먹는다'를 번역할 때, 'I', 'apple'등 관련된 단어들에 더 높은 가중치를 부여해 문맥을 반영합니다. 즉, 하나의 시퀀스(Query)를 기준으로 다른 시퀀스(Key, Value)에서 관련된 정보를 찾아 집중합니다.
반면, Self Attention은 단인 데이터 시퀀스 내부의 관계를 파악하는 데 사용됩니다. 문장 내 단어 간의 관계를 분석하여 문맥을 이해하는 데 효과적입니다. "고양이가 생선을 맛있게 먹었다"에서 "먹었다"이라는 단어의 Query, Key, Value 벡터를 생성하고 같은 문장 내 다른 단어들과의 관계를 계산합니다. "고양이가", "생선을" 과의 연관성이 높게 나타날 것입니다. 즉, 하나의 시퀀스 내에서 각 단어가 다른 단어들과 얼마나 관련되어 있는지 파악합니다.
| Encoder-Decoder Attention | Self-Attention | |
| 데이터 시퀀스 | 2개 이상 | 단일 시퀀스 |
| 목적 | 시퀀스 간 관계 파악 | 시퀀스 내부 관계 파악 |
| 활용 예시 | 번역 모델(encoder-decoder) | 문맥 이해 |
2. Self-Attention 작동 방식
Self-Attention은 Query, Key, Value를 사용해 단어 간의 관계를 파악합니다. 아래의 순서에 따라 Self-Attention이 작동합니다.
1. 입력 문장의 각 단어를 Query, Key, Value 벡터로 변환합니다.
2. 각 단어의 Query 벡터와 문장 내 모든 단어의 Key 벡터를 비교해 유사도(Attention Score)를 계산합니다.(Scaled Dot-Product)
3. 유사도를 기반으로 각 단어의 Value 벡터에 가중치를 부여하고 가중치가 부여된 Value 벡터들을 합산하여 문맥 정보가 반영된 벡터를 만듭니다.
2-1. 입력 문장의 각 단어를 Query, Key, Value 벡터로 변환합니다.

Query, Key, Value는 입력 데이터(단어)를 임베딩한 후, 각각의 Linear Layer를 통과시켜 계산됩니다.
Query의 Linear Layer, Key의 Linear Layer, Value의 Linear Layer은 모두 다른 가중치를 갖고 있습니다.
입력 벡터에 가중치 행렬을 곱해 Query, Key, Value를 만듭니다. (bias는 더하지 않습니다.)
결국 Self Attention의 Query, Key, Value는 모두 동일한 정보로부터 선형변환을 통해 만들어졌다고 할 수 있습니다. 시작 값이 단어의 이메딩 값으로 같기 때문에 Self를 붙이는 겁니다.
- Query: 지금 당장 처리하고 있는 토큰의 벡터(현재 단어가 다른 단어들에게 던지는 질문(ex. "나랑 관련 있는 단어 있어?"))
- Key: 다른 모든 토큰의 벡터(다른 단어들이 Query에 대한 답변으로 내놓는 정보(ex. "난 고양이야", "난 생선이야"))
- Value: 다른 모든 토큰의 벡터(각 단어가 가진 정보 자체(ex. "고양이는 귀엽지", "생선은 맛있어"))
2-2. 각 단어의 Query 벡터와 문장 내 모든 단어의 Key 벡터를 비교해 유사도(Attention Score)를 계산합니다. (Scaled Dot-Product)
Attention Score은 Query 벡터와 Key 벡터 사이의 유사도를 나타내는 점수입니다. 다시 말해, 현재 처리 중인 단어(Query)가 입력 데이터에 있는 단어들(Key)과의 유사도를 구하는 과정입니다. Attention Score가 높을수록 두 단어가 서로 관련성이 높다는 것을 의미합니다. "😋"라는 Query는 "😺"와 "🐟"의 key와 높은 점수를 가질 것입니다.
🧮 수식
예를 들어, "😺"과 나머지 단어들("😺", "🐟", "😋", "🍽️")과의 유사도를 구한다고 해봅시다.
Attention Score(q, K) = (q*K^T) / sqrt(d_k)
- q: ("고양이가"의)Query 벡터
- K^T: Key matrix transpose
- d_k: Key matrix 차원
나머지 단어들도 한번에 계산한다고 하면 수식은 다음과 같이 됩니다.
Attention Score(Q, K) = (Q*K^T) / sqrt(d_k)
- Q: Query matrix
- K^T: Key matrix transpose
- d_k: Key matrix 차원
📌 sqrt(d_k)로 나누는 이유
여기서 Key matrix 차원의 제곱근으로 나누는 이유는 Scaling하기 위해서입니다. Scaling하지 않고 softmax 함수에 통과하면 큰 값들로 인해 softmax 분포가 지나치게 편향될 수 있습니다. 특정 Key에 대한 확률값이 1에 매우 가까워지고 나머지는 0에 가까워질 수 있습니다. Scaling을 했기 때문에 그냥 dot-product attention이 아니라 scaled dot-product attention입니다.
2-3. 유사도를 기반으로 각 단어의 Value 벡터에 가중치를 부여하고 가중치가 부여된 Value 벡터들을 합산하여 문맥 정보가 반영된 벡터를 만듭니다.
Attentions score를 softmax 함수에 통과해 확률 분포로 변환합니다. 각 단어에 대한 Attention Weight의 합이 1이 되도록 합니다.
🧮 수식
Attention Weight(Q, K) = softmax(Attention Score(Q, k))
각 단어에 대한 Attention Weight를 각 단어의 Value와 곱합니다. 즉, 현재 처리하고 있는 단어(Query)에 대한 각 단어들의 가중치(Attention Weight)를 구하고 이를 각 단어들의 Value와 곱함(가중합)으로써 현재 처리 중인 단어와 단어 사이의 관계에 대해 계산합니다. "먹었다"라는 단어는 "고양이"와 "생선"의 Value에 높은 가중치를 부여하고 다른 단어들의 Value에는 낮은 가중치를 부여하게 됩니다.
가중치가 부여된 Value들을 모두 더하면 문맥 정보가 담긴 최종 벡터가 만들어집니다. "먹었다"라는 단어는 "고양이"와 "생선"의 정보를 충분히 반영하게 되었습니다.
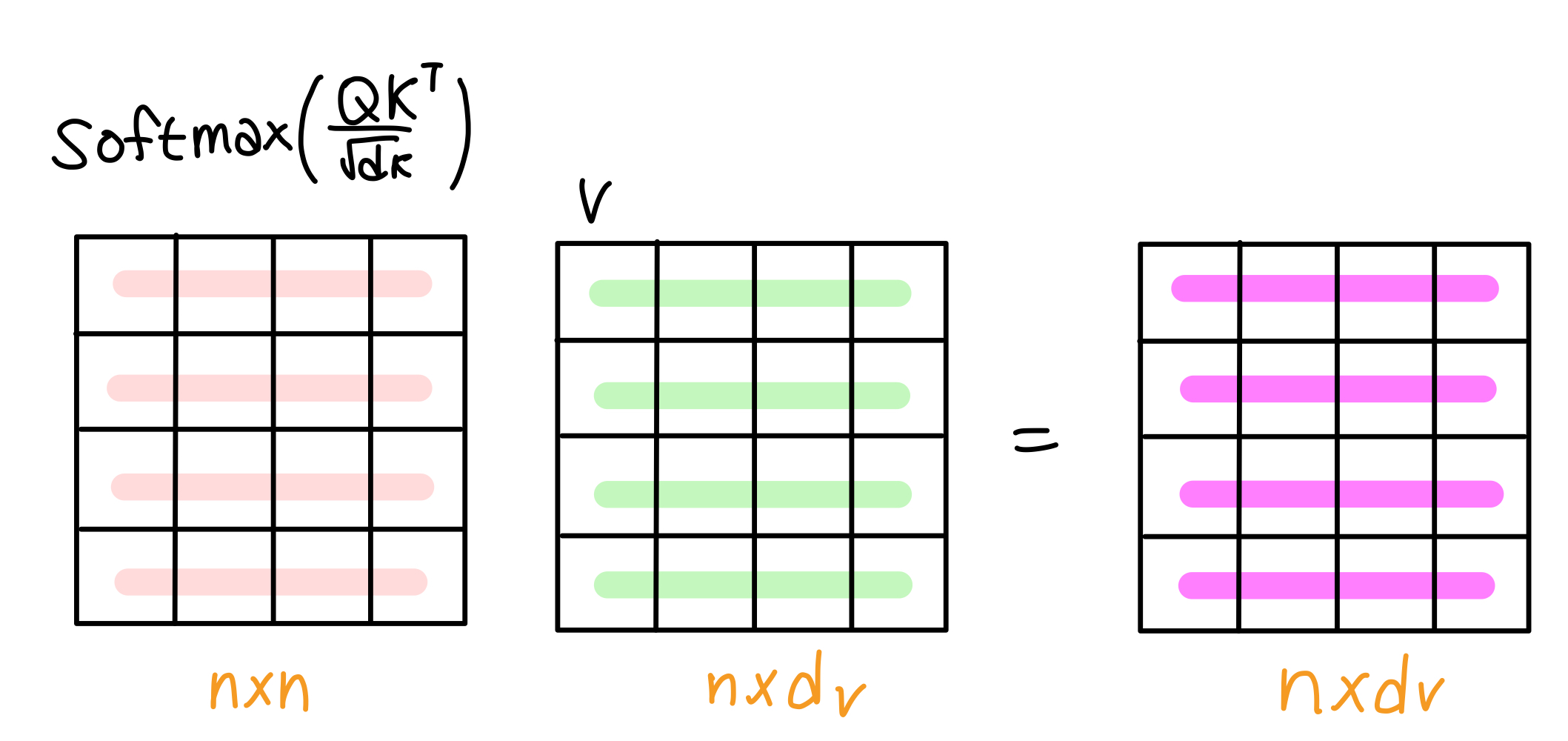
🧮 수식
Attention(Q, K, V) = Attention Weight(Q, K)V
3. Self-Attention의 장점
- 문장의 전체 문맥 파악 가능: RNN처럼 순차적으로 정보를 처리하지 않고 문장 전체를 한 번에 고려하여 RNN보다 문맥을 잘 파악할 수 있습니다.
- 병렬 처리 가능: 각 단어의 Attention Score을 한번에 계산할 수 있어서 빠르게 연산할 수 있습니다.
- 장기 의존성 해결: 문장 길이에 제한 없이 멀리 떨어진 단어 간의 관계도 효과적으로 파악할 수 있습니다.
Reference
https://velog.io/@nkw011/transformer
'Artificial Intelligence' 카테고리의 다른 글
| [Transformer] Transformer 모델 종류 (0) | 2024.06.17 |
|---|---|
| [Transformer] Masked Self-Attention (0) | 2024.06.13 |
| 지도학습 vs 비지도학습 (0) | 2024.05.31 |
| [인공지능 기초 지식] 평가지표 (0) | 2024.05.20 |
| [인공지능 기초 지식] Activation Function 활성화 함수 (0) | 2024.05.13 |